Welcome to module three. In this section, we will be discussing about How do we make meaning of this large corpus of tweets? What are systematic approaches to data analysis ?
Overview of module:
1. Brief introduction to approaches for data analysis
2. Sampling
1. Brief Introduction to Approaches for Data Analysis
Additional resources
Dictionary based Text Analysis: https://sicss.io/2019/materials/day3-text-analysis/dictionary-methods/rmarkdown/Dictionary-Based_Text_Analysis.html
Topic Modeling: https://cbail.github.io/SICSS_Topic_Modeling.html
Grounded Theory:https://www.depts.ttu.edu/education/our-people/Faculty/additional_pages/duemer/epsy_5382_class_materials/Grounded-theory-methodology.pdf
2. Sampling
A random sample is when all observations/respondents in a population have an equal chance of being selected. For eg picking a number for bingo. For our project, an easy way to do this is to use a random number generator and select corresponding tweets from the TAGS archive.
A purposive sample is when you select a sample of tweets, based on certain criteria. This criteria will depend on your topic of interest or your research question. For example, you might decide to select tweets of those residing in a certain region or in tweets by users of mental health services. In the former case, you can easily shortlist regions of interest by selecting relevant categories under “user_location” (Column P).
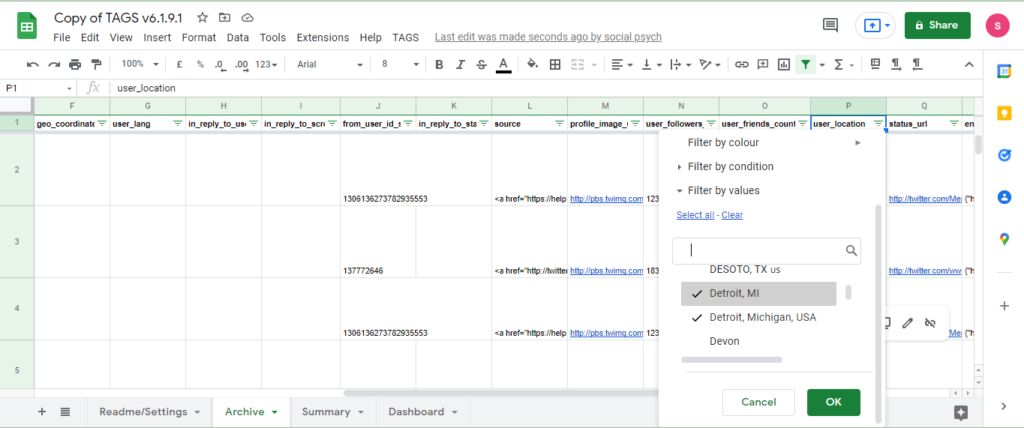
Note: If the number of tweets in your purposive sample is high , you might want to use a random number generator to select tweets from within the category